Naïve Bayes Classifier
Naïve Bayes Classifier
Classfication base review(有一说一,感觉又可以略过..
Response values
- Nominal Categorical
- Binary
- Multi-class
- Ordinal Categorical
- Discrete Numerical
output
- Single class value(类别标签,如SVM, kNN, Decision Tree)
- Score for positive class label.(正类的概率值(需要设定threshold的那种),如Logistic Regression, ANN)
- Score for all class labels(所有类别的概率值(最后选择
最大的),如Multi-class SVM, ANN)
logic
- Response can be calculated by adding and/or rescaling input feature values(基于函数学习的模型,如Linear Regression, ANN)
- Response is assumed to be same/similar among “similar” samples(基于相似性的模型,如kNN, Decision Tree)
Bayes Classifier
Calculate probability from data
in which:
- is the class label
- is the feature vector
- is the posterior probability of class given feature vector (给定特征的条件概率..?)
我们希望的,是找到一个 使得 最大化。
Bayes' theorem
而由于 是常数,对于每个 来说都是一样的,所以我们可以忽略掉它:
所以我们最终得到了(Naïve) assumption of conditional independence:
重新整理一下,Full Bayes Classifier就是:
Laplace smoothing
比如某个类别下,某�个特征的值没有出现过,那么 就会是0,这样就会导致整个乘积为0。
为了解决这个问题,我们可以使用Laplace smoothing:
即给每个特征的值加上一个小的常数,比如
举个例子:

就比如说这个 , 我们就 +1,变成了 -- 因为Fur color这个特征有4个类别,各都要跟着 +1
Diff input data types -> Diff Naïve Bayes
- Gaussian Naïve Bayes:
连续值,且服从正态分布。 是用高斯概率密度函数来计算的。(懒得管具体是啥了.. - Multinomial Naïve Bayes: 离散值。
- Categorical Naïve Bayes: Categorical值。
-
Gaussian Naïve Bayes 常用于numrical inputs的分类:
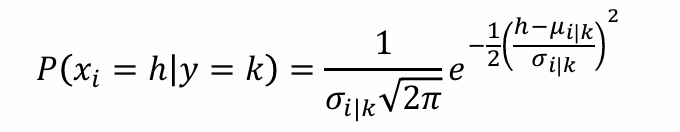
-
Multinomial Naïve Bayes 常用于文本分类 -- 文本被转化为
bag of words.
Eva (可以参考kNN & Decision Tree的Comparision部分)
-
Can predict the response / label for a new data?
Y -
Easy to interpret? (Using intuitive logic)
Y -
Defines real relationships b/w features and response?
Maybe
Cuz we assume the features are independent, but in reality they might be not, which will make the ability of its "Relationship Modeling" weak. -
Model is fast / easy to store / share / optimize/ apply?
Y. 只存了概率表 -
Few hyperparameters?
Y -
Use data with minimal preprocessing?
Y -
Potentially useful?
Y -
Used to validate a hypothesis?
Y/N?
毕竟朴素贝叶斯本身只是个模型,不是个假设验证的工具。 -
Find novel interpretation of data?
N !!!
朴素贝叶斯的结构很扁平, 相对于kNN和Decision Tree来说。所以不具备自动发现复杂数据结构的能力。